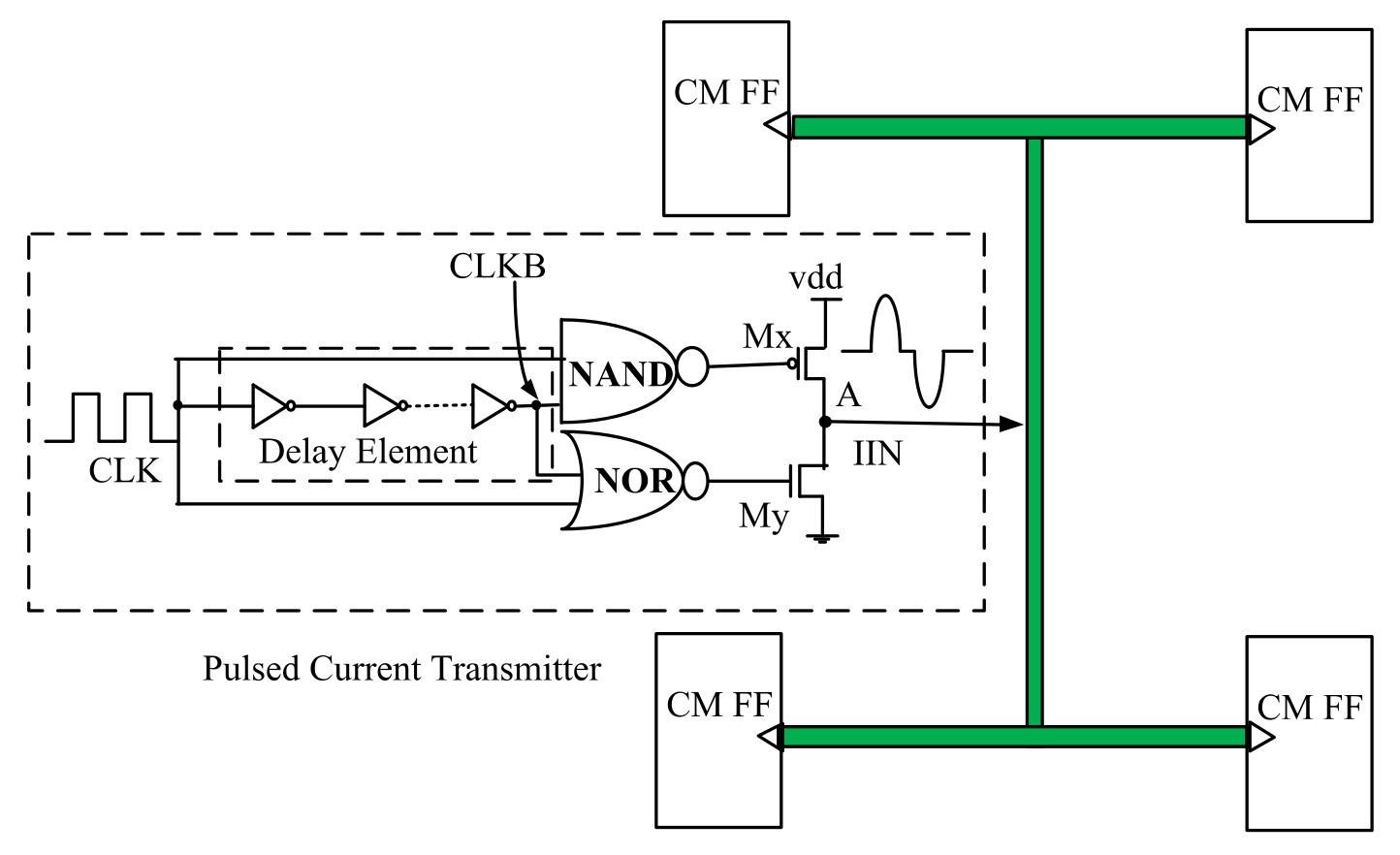
Current-Mode Clock Distribution (Low-power, Highly Robust)
I propose a new paradigm for clock distribution that uses current, rather than voltage, to distribute a global clock signal with reduced power consumption. While current-mode (CM) signaling has been used in one-to-one signals, this is the first usage in a one-to-many clock distribution network. To accomplish this, we create a new high-performance current-mode pulsed flip-flop
(CMPFF) using a representative 45nm CMOS technology. When the CMPFF is combined with a CM transmitter, the first CM
clock distribution network exhibits 40-60% lower average power compared to traditional voltage mode clocks.
Differential Current-Mode Clock Distribution
I present a differential current-mode pulsed flip-flop (DCMPFF) for low-power clock distribution using a representative 45nm CMOS technology. Experimental results show that the DCMPFF has 47% faster clock-to-output (CLK-Q) delay than a traditional voltage-mode (VM) pulsed flip-flop. When the DCMPFF is integrated with a differential current-mode clock distribution, the differential technique saves 62% and 17% power compared to a conventional VM and a previous current-mode (CM) clock network, respectively.

CMCS: Current-Mode Clock Synthesis
In a high-performance VLSI design, the clock network consumes a significant amount of power. While most existing methodologies use voltage-mode (VM) signaling, these clock distributions lose a tremendous amount of dynamic power
to charge/discharge the large global clock capacitance. New circuit approaches for current-mode (CM) clocking save significant clock power, but have been limited to only symmetric networks, while most application specific integrated circuits (ASICs) have asymmetric clock distributions. I propose the first CM clock synthesis (CMCS) methodology to reduce overall clock network power with low skew. The method can integrate with traditional clock routing followed by transmitter and receiver sizing. We validate the proposed methodology using ISPD 2009 and 2010 industrial benchmarks using an extracted spice model distributed in 1.4-275.6 mm^2 area and consists of 81-2249 sinks. This methodology saves 39-84% average power with similar skew on the benchmarks using 45nm CMOS technology simulation of clock frequencies range from 1-3GHz. In addition, the CMCS methodology takes 2.4-9.1x less running time and consumes $20-26%$ less transistor
area compared to synthesized, buffered VM clock distributions.


